Representative Sampling Algorithm
Bayesian stopping algorithm for representative sampling from empirical datasets
An algorithm implementation for selecting representative samples from large empirical datasets using a Bayesian stopping rule.
The workflow is based on the realisation-dependent stopping criterion (Algorithm 1, Quinn and Kárný, Int. J. Adapt. Control Signal Process., 2007), and was adapted here for practical representative sampling in research datasets.
Developed in the context of brain injury biomechanics, the project provides a principled way to reduce large datasets into compact representative subsets before expensive downstream simulation or analysis.
GitHub repository
The open-source repository contains the Python implementation, example scripts, helper functions, and visual outputs for demonstrating Bayesian representative sampling.
View GitHub repository →Reducing sample size
The algorithm draws a compact subset from a larger empirical dataset, allowing expensive downstream simulations or analyses to be performed on fewer representative cases.
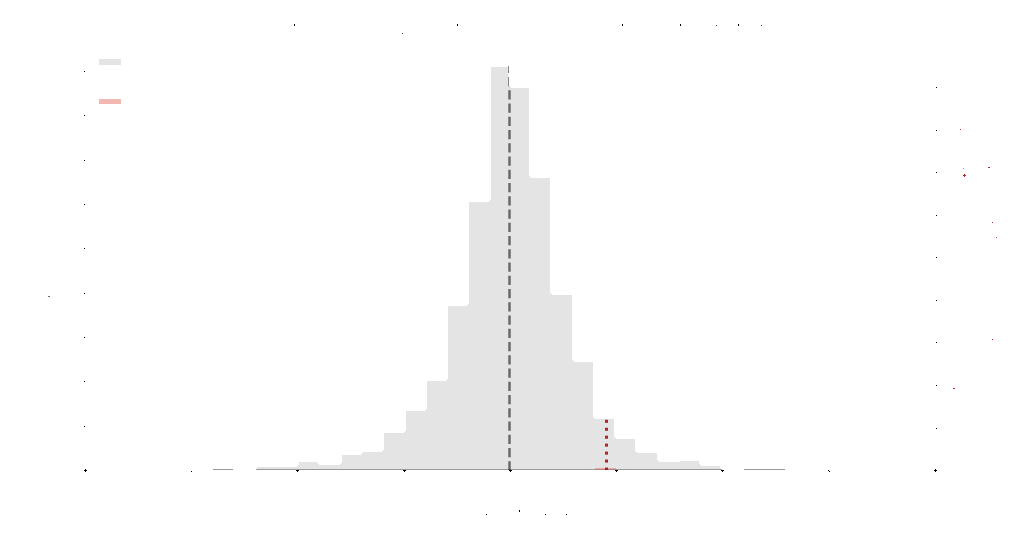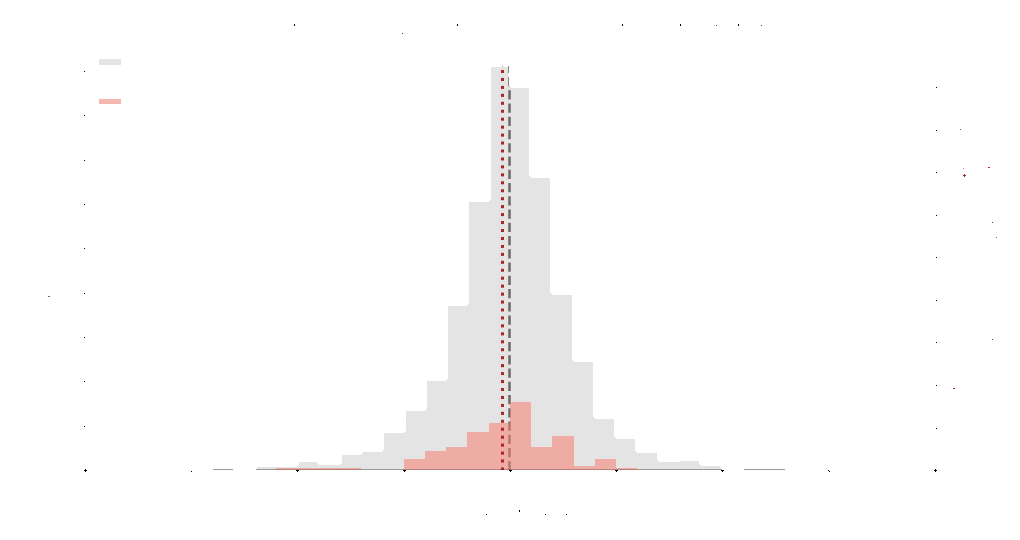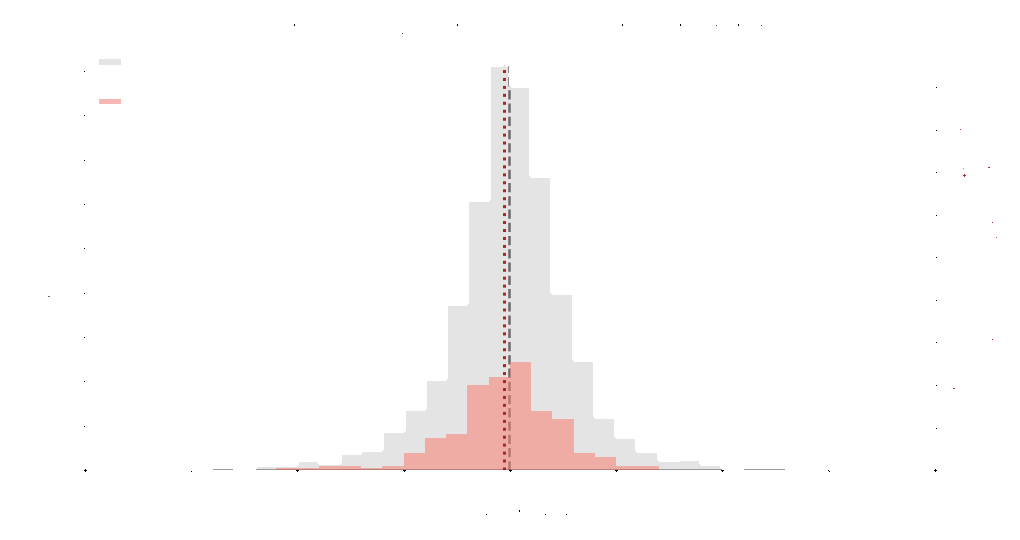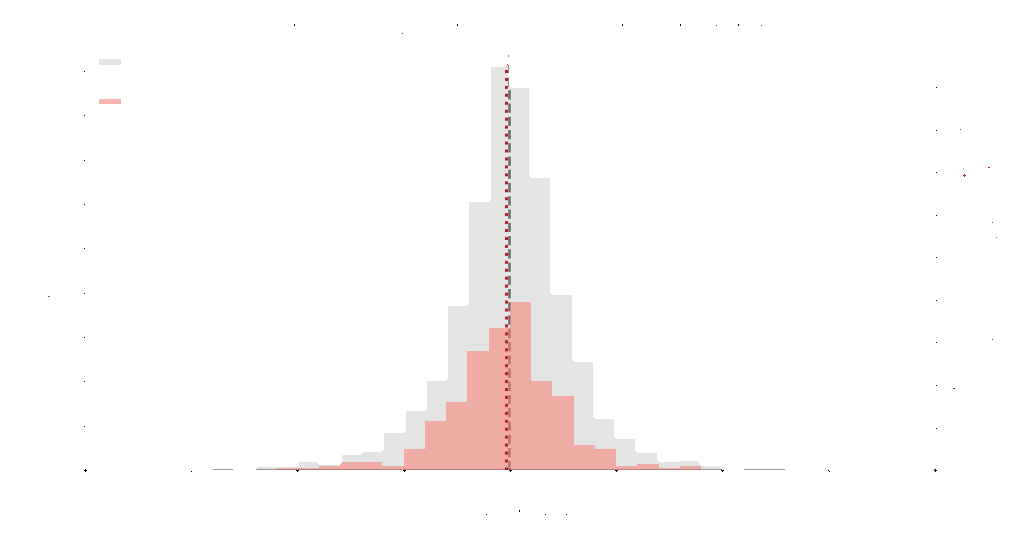
Example on the right shown using an empirical Student-t distribution. Grey indicates the original distribution and pink indicates the sampled representatives. With a stopping tolerance of \(\epsilon = 0.1\), the algorithm selected 391 samples from an original dataset of 5000 samples.
Adjustable stopping tolerance
A stopping tolerance \(\epsilon\) controls how strict the sampling process should be. The algorithm monitors the Kullback–Leibler divergence between successive estimates, which measures how much the estimated distribution changes after adding a new sample.
Sampling stops when this information change falls below the tolerance. Smaller tolerances require stronger convergence and usually select more samples, while larger tolerances stop earlier.
Evaluating representativeness via a statistic of choice
The selected subset can be evaluated against the original empirical distribution via a statistic of choice, such as sample mean or median, providing a diagnostic for how well the reduced sample preserves the behaviour of the full dataset.
In practice, this means checking whether the selected samples retain the key distributional structure of the original data, rather than simply reducing the dataset at random.
Representative sampling makes large computational studies more tractable and less dependent on manual case selection.